Demystifying the Kubernetes Iceberg: Part 1
Categories:
6 minute read
A while ago, u/dshurupov published a picture on Reddit that I called “The Kubernetes Iceberg.” The picture was made by the folks in Flant.
It represents a vast iceberg, where on the top you have some of the simplest concepts of Kubernetes, and as you go below and underwater, you dive deeper into more advanced Kubernetes subjects. This is the picture:
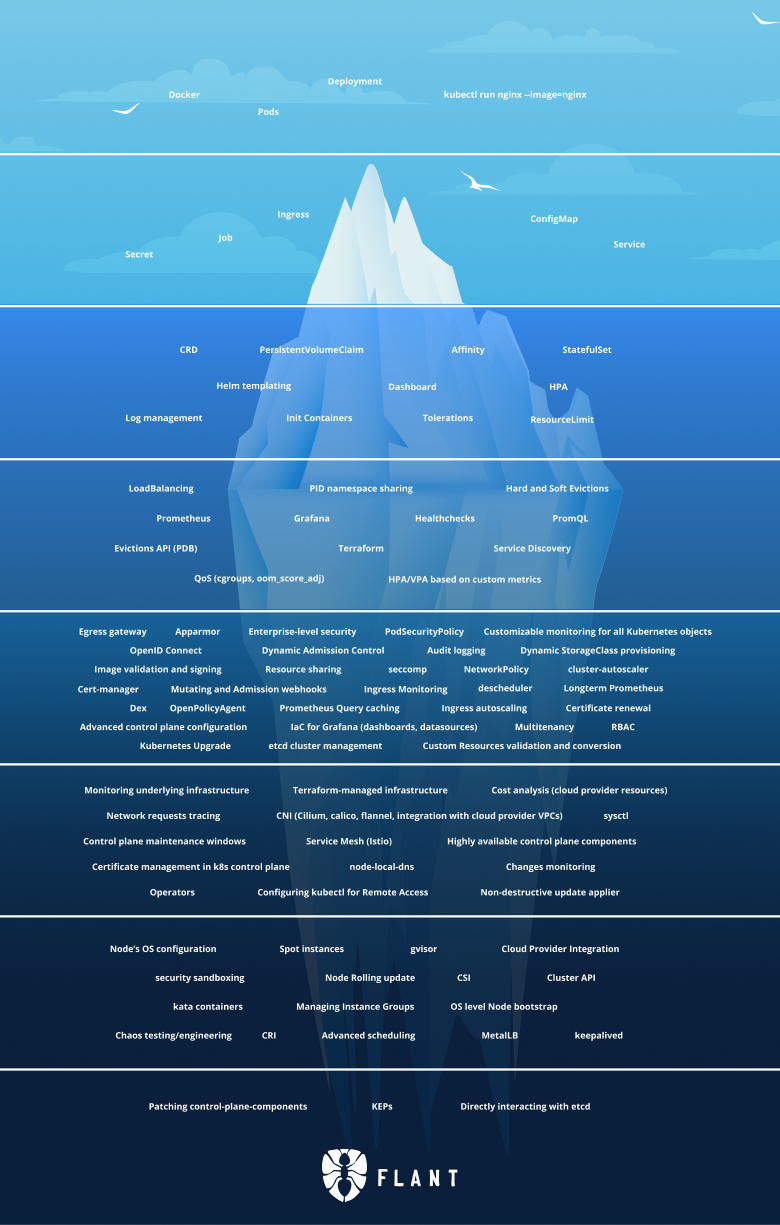
When I saw it, I thought it was brilliant. Kubernetes is not easy to start with, and it is precisely like an iceberg. The more you learn, the more you realize you have even more to learn.
In this series of articles, I aim to go over each of the concepts present in the iceberg and explain them in the simplest way possible. Since the explanations will not be exhaustive, I will add additional links to my sources to continue the learning outside of my blog.
The iceberg is quite vast, so I will split this into several articles, publishing one each week.
This is the first article where I explain the first two levels of the iceberg.
NOTE: Even though I have been working with Kubernetes for almost three years at the time of this writing, I still don’t consider myself a Kubernetes expert. In fact, I was also not familiar with some of the more advanced concepts here, so I had to do some learning myself. And this is one of the reasons for writing this series of articles. So that we can learn and grow together, both my readers and me.
Strap on; it’s going to be a fun ride!
Tier 1
Docker
Docker is a container runtime. It was introduced to the world in a lightning talk at PyCon US 2013, previously being the backbone of a PaaS company called dotCloud.
It revolutionized the way we build and deploy software, using age-old Linux concepts like cgroups and namespaces, but providing a friendly and easy-to-use interface on top of that.
Nowadays, there is an open standard for container images and runtimes called OCI - Open Container Initiative.
Docker images are OCI-compatible, but the Docker runtime is not.
One of the compatible runtimes is containerd, which is also used by Docker under the hood.
Containerd is a lower-level container runtime that can run OCI images (including ones built with Docker).
Because Docker is not OCI-compatible, it is not supported as Kubernetes runtime anymore (but Docker images ARE OCI-compatible, so you can still run them in Kubernetes).
This requires an additional component (called dockershim) to be the bridge between Docker and Kubernetes.
The Kubernetes community maintained this component, but they don’t want to do that anymore since there are already many reliable OCI-compatible alternatives (containerd being one of them).
Pods
Pod is a Kubernetes object that represents a workload.
It is the smallest possible building block in Kubernetes.
A pod can contain one or more containers. A pod should contain more than one container only if these containers are required to share memory and disk.
Pods are ephemeral and disposable. A standalone Pod that dies or gets deleted won’t be recreated, so your workload will just stop running if that happens.
That is why we have…
Deployments
Deployment is a Kubernetes object that represents a workload.
It specifies an image and the number of desired replicas. Kubernetes makes sure that the number of running replicas always matches the desired one. For example, if we create a Deployment with three replicas, Kubernetes will create 3 Pods (one for each replica). If any of the Pods gets deleted or dies, Kubernetes will spin up a new one to match the actual state of the cluster to the desired state.
Automatic recreation of failed workloads is one of the best Kubernetes features and a big reason why Kubernetes is so popular nowadays.
kubectl run nginx —image=nginx
kubectl is a CLI for interacting with Kubernetes.
You can install it on your machine and use it to interact with every Kubernetes cluster.
The Kubernetes cluster you interact with and the way you interact with it (network location, API keys, certificates, etc.) is stored in a kubeconfig file.
One of the commands of kubectl is kubectl run.
This command will create a Pod with the image specified by the --image flag.
In this case, the image is nginx, and the Pod name is also nginx.
Tier 2
Secret
Secret is a Kubernetes object for storing… well, secrets.
Once you create a Secret, the workloads running in your cluster can access that and use it.
However, using the native Secret object is discouraged because Secrets in Kubernetes are not actually secret.
Kubernetes stores Secret values in plain text after base64 encoding them.
That means it’s effortless for an attacker to steal them if they manage to hack inside your cluster.
Job
Job is a Kubernetes object representing a temporary workload that will run to complete a job and then exit.
For example, you can have a Job that will start a Pod to do dome cleanup work.
After the Pod finishes, it will exit and never start again (there are other types of Jobs, if this is what you want).
ConfigMap
ConfigMap is a Kubernetes object for storing configuration in the format of key-value pairs.
Once you create a ConfigMap, your can configure your workloads to use its values.
Service
Service is a Kubernetes object that provides an abstraction point over a group of pods based on label selectors.
When Pods are created in Kubernetes, each one of them is assigned an IP address. However, we said that Pods are ephemeral, and when one dies, it is never restarted. Instead, a new one is created, which means it gets a new IP address. This means that we cannot depend on Pods’ IP addresses because they can change without notice.
This is where Services come in. A Service will wrap a group of Pods based on their labels. If a Pod dies, a new one will be created. The new one will have a new IP but the same labels, so the Service will pick it up and start sending traffic to it. That way, we have a stable interface to a shifting pool of workloads.
Ingress
Ingress is a Kubernetes object that manages the external traffic coming into the cluster.
An Ingress object can be configured to send traffic to different Services inside the cluster, based on path or hostname.
The Ingress object is an abstract one. It only provides the configuration. The implementation of the ingress, e.g., the routing, is provided by additional components like the nginx ingress controller. Kubernetes users are responsible for choosing the implementation and providing it (deploying the controllers).
Summary
This is all for part one. I hope you enjoyed it and learned something new.
The series continues with Part 2.
If you don’t want to miss on more of my content, you can follow me on Twitter or LinkedIn.